
Der aktuelle KI-Boom nervt und fasziniert mich gleichzeitig. Ich glaube auch, dass die Technologie das Potenzial hat, uns zu helfen (denke „Erkennung von Krebs in MRT-Bildern“), aber sie macht mir ebenso Angst (denke „Massenüberwachung“). Und zuletzt gibt es natürlich noch das Problem, dass jede Form generativer KI auf Trainingsdaten beruht, deren Urheber sicher „nicht immer“ ihr Okay für deren Verwendung gegeben haben. Aber darum soll es heute nicht gehen.
Ich spiele seit einer Weile mit Open-Source-Modellen, wie z. B. Stable Diffusion, zur Erzeugung von Bildern herum. Im Grunde funktioniert das so, wie man es aus dem Web kennt: Man gibt einen Prompt ein, der das Bild beschreibt, wartet, und ein mehr oder weniger sinnhaftes Ergebnis purzelt aus der Maschine. Der große Unterschied ist, dass lokal ausgeführte Modelle den eigenen Rechner lauschig warm werden lassen und nicht einen entfernten. Zudem sind lokale Modelle nicht moderiert. Öffentliche Modelle sagen ja öfter mal „Nein“, wenn sie glauben, dass der Prompt „Darth Vader trinkt Bier im Pub“ gegen ihre Richtlinien verstößt.
Generative Bildmodelle wie Stable Diffusion funktionieren ganz grob gesagt (KI ist nicht mein Fachgebiet) so: Sie nutzen eine Technik namens Diffusion, um aus Rauschen (denke Rauschen vom Fernseher, der keinen Empfang hat) ein Bild zu erzeugen. Die eigentlichen Diffusionsschritte laufen jedoch nicht direkt auf den Pixeln, sondern in einem komprimierten latenten Raum, der zuvor von einer Software-Komponente namens Variational Autoencoder (VAE) erzeugt wurde. Dieser VAE hat mit vielen, vielen Trainingsdaten gelernt, erst hochdimensionale Daten (also Bilder) in eine niedrigerdimensionale Darstellung zu komprimieren („Encoding“) und diese komprimierte Darstellung wieder zurück in ein Bild zu verwandeln („Decoding“). Das decodierte Bild wird dem Urbild ähneln, aber es wird niemals identisch sein.
Der große Trick an Stable Diffusion ist, dass man durch einen Prompt sozusagen ausdrücken kann, „in was“ Rauschen über mehrere Diffusionsschritte entrauscht wird. Bei einem Prompt wie „eine Banane auf einem Holztisch“ wird das Rauschen schrittweise verfeinert, bis eine Banane auf einem Tisch erzeugt wurde. Und „Banane auf dem Mars“ erzeugt … leider keine Banane auf dem Schokoriegel.


Das Interessante ist nun, dass man den Diffusionsprozess nicht nur mit Rauschen starten kann, sondern auch mit einem realen Foto, welches man zunächst encodiert. Der Diffusionsprozess wird dann nicht mit Rauschen (also bei Null) gestartet, sondern verändert ein bereits fertiges Bild. Die Richtung, in die die Veränderung wirkt, kann durch einen Prompt gesteuert werden. Der Grad der Veränderung wird über einen sogenannten Denoise-Wert bestimmt, der ausdrückt, wie viel vom ursprünglichen Bild ersetzt wird. (Es ist auch möglich, den Effekt auf nur einen kleinen Teil des Bilds anzuwenden, was wir dann als Inpainting bezeichnen.)
Damit man sich das Ganze besser vorstellen kann, habe ich da mal etwas vorbereitet: Das ist ein Bild, welches ich im Januar in Venedig aufgenommen habe. Durch leichten Dunst in der Luft und zusätzlich entsprechende Bearbeitung sieht es per se schon fast wie ein impressionistisches Gemälde aus.

Das Bild kann man nun mithilfe der oben umrissenen Methode verändern. Als Prompt habe ich mir Folgendes überlegt:
„colorful night scene in Venice, impressionistic oil painting, thick brush strokes, visible brush strokes, paint texture, emphasize vibrant colors, dynamic brush strokes, capture the play of light on the water, reflect the buildings, convey a lively atmosphere, use bold expressive colors, focus on emotion and movement, simplify forms, concentrate on overall composition rather than realistic details.“
Denoise-Werte sind 0.2, 0.4, 0.5, 0.6, 0.7, 0.73, 0.75. Charakteristisch an dem Prozess ist, dass bis 0.7 das Bild erkennbar bleibt. Irgendwo zwischen 0.71 und 0.75 löst sich das Bild in Wohlgefallen auf. Das letzte Bild ist komplett aus dem Äther, also aus Rauschen, erzeugt.








Und jetzt stellt sich die Frage: Ist das Kunst, oder kann das weg? Ich weiß es auch nicht, aber ich finde das Ganze eine recht interessante Spielerei. Bildbearbeitung „next generation“, quasi.
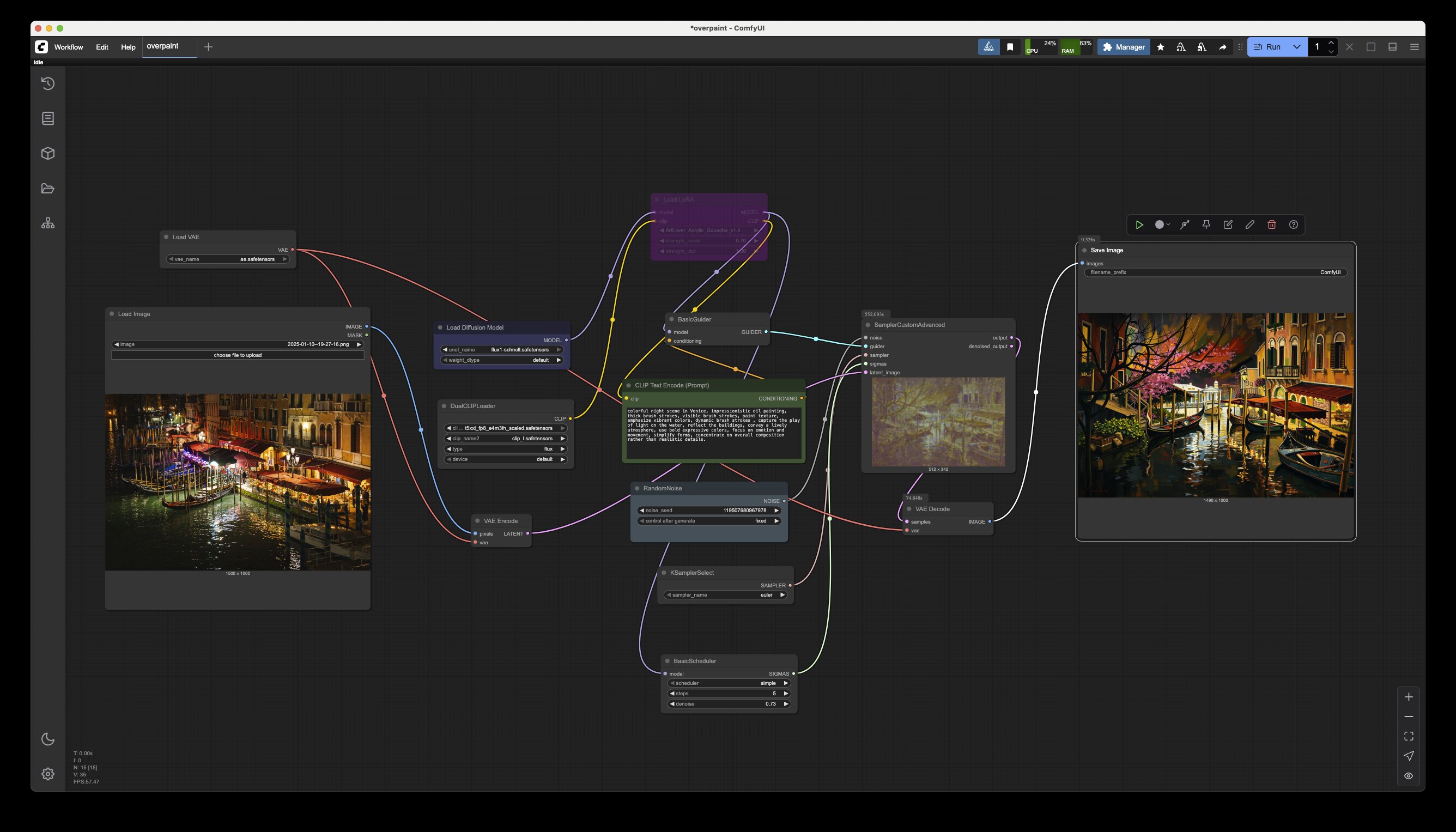
Wer sich jetzt fragt: Welches Tooling nutzt du da? Das Modell heißt FLUX (ein Nachfolger von Stable Diffusion; die „Schnell“-Variante ist Apache-2.0-lizenziert, andere Editionen sind proprietär) und das Tool, das den Spaß erst bedienbar macht, ComfyUI. Unten ist ein Screenshot der Anwendung. Die Boxen entsprechen verschiedenen Funktionen, wie z. B. „Bild laden“, „encoden“, „diffundieren“, usw. Solche Workflows kann man sich aus dem Web besorgen und die Modelle natürlich auch. Eine gute Quelle ist z. B. Hugging Face.
Schreibe einen Kommentar